
Python web scraping with Playwright
December 14, 2022 / 22 min read / 7,087 , 1 , 0
Tags: python, flask, web, web-scraping, playwright, tutorial, testing

Web scraping is the concept of programmatically collecting data from a website. This article will discuss using Playwright for python web scraping. The most popular web-scraping packages for python are requests and Beautiful Soup used together. This combination is potent and straightforward to use for most web pages. However, the use case has limitations because the combination relies on making server requests and reading the static HTML returned. It can be challenging to scrape single-page applications (SPAs) or websites where the objects to scrape are only available after some javascript interactions. Playwright circumvents these limitations by interacting with web pages like humans to find the data that needs scraping.
The problem
Fun fact about me. I swing dance competitively (although I'm still a novice). Competitive swing dancing events award points to competitors who place well in competitions. As a dancer gains points, they can move up through divisions ("newcomer", "novice", "intermediate", "advanced", or "allstar"). Those points are stored with the Wold Swing Dance Council (WSDC). The WSDC has a website page where you can look up any dancer by their name or dancer ID to see what division the dancer is in and how many points they have in that division.
I wanted to create a web page allowing users to search for dancers and return the same data as the WSDC dancer lookup page. The problem is that the lookup on that webpage uses javascript to make AJAX requests to update the page with dancer point data asynchronously. This type of request is difficult to replicate and scrape with the python "requests" and "Beautiful Soup" libraries. So I'm going to scrape the page with Playwright.
What is Playwright?
Playwright bills itself as a framework for "... end-to-end testing modern web apps". It is a tool like Selenium that allows the user to write python code (or Node.js, Java, or .NET code) to open a web browser and interact with a web application as a human would. Playwright can programmatically perform any action a human user can perform, such as typing into an input box and clicking a submit button. I recommend checking out my other blog post on Playwright, "End-to-end website testing with Playwright", which goes into depth on how Playwright works and how you can use it for testing your website.
Setup
You can find all the code for this web scraping example on GitHub here. I wrote the code for python 3.10, but it should work in python versions 3.9+ (or lower versions of python if type hints are removed). You can also see a finished code version toward the end of the article, here. To get started with the examples, first, create a virtual environment. Then pip install the packages we'll be using into that virtual environment:
pip install flask playwright pytest
Playwright requires an additional installation step to install the browsers it uses for interacting with websites:
playwright install
And we're all set.
Generating the initial script with "codegen"
Playwright has a nifty tool called "codegen" to help you start writing a playwright script. Here's the command line argument I typed to get an outline of my script:
playwright codegen https://www.worldsdc.com/registry-points/
This command opened two windows: a web browser to the page https://www.worldsdc.com/registry-points/ that I want to web-scrape and a second window with some buttons and python code. I then interacted with the website exactly as I would to get a swing dancer's data. I clicked the search box, typed in my name, and clicked the dropdown link for myself, filling the page with my competitive swing dance data. Here's a GIF of how those steps looked:
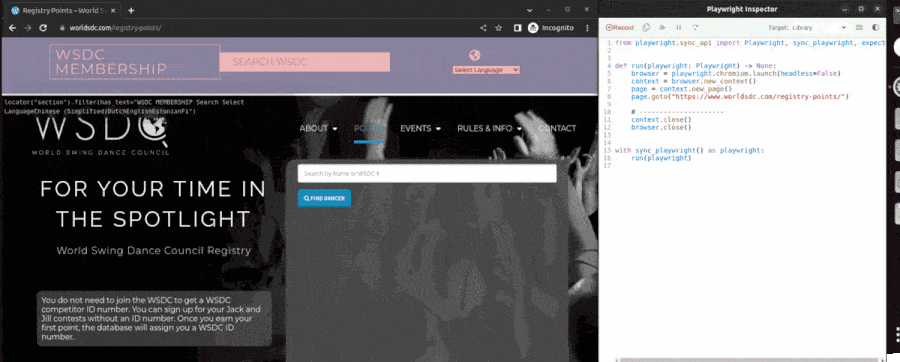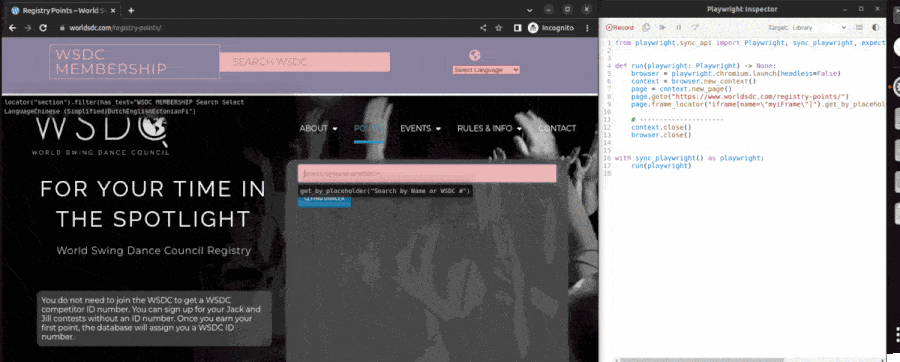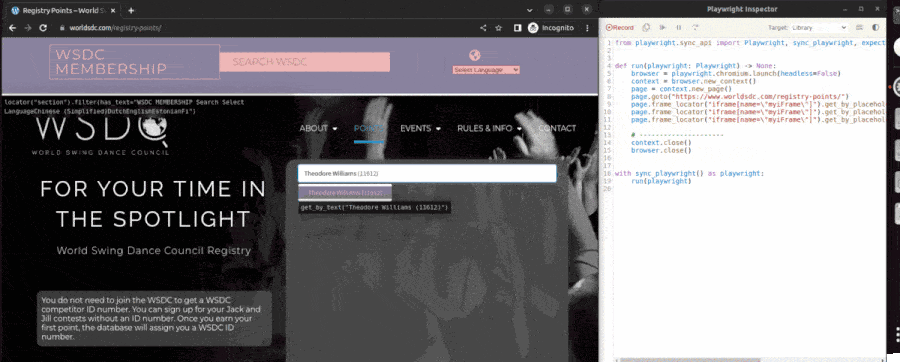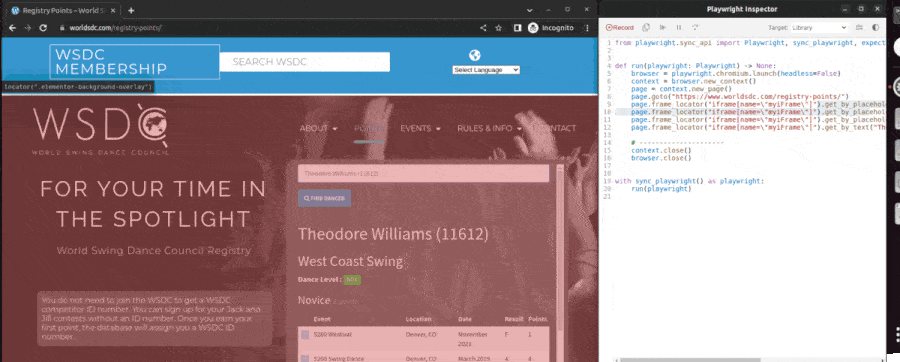 The Playwright codegen tool wrote an initial script.
The Playwright codegen tool wrote an initial script.
As I performed these actions, the second window filled out a Playwright script to replicate my steps. Here's the script it generated:
from Playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.worldsdc.com/registry-points/")
page.frame_locator("iframe[name=\"myiFrame\"]").get_by_placeholder("Search by Name or WSDC #").click()
page.frame_locator("iframe[name=\"myiFrame\"]").get_by_placeholder("Search by Name or WSDC #").fill("theodore williams")
page.frame_locator("iframe[name=\"myiFrame\"]").get_by_text("Theodore Williams (11612)").click()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
This auto-generated script was a great first step. I saved the script to a file named check_dancer_points.py. When I ran the script, it did what I wanted it to do, although quickly, so it was hard to see what was happening. So, I adjusted the "browser" line to see what's happening more easily: browser = playwright.chromium.launch(headless=False, slow_mo=1000). Now when I run the script, there is a 1-second (1000 millisecond) pause between each action, and I can see that the script is performing the expected actions. Here's what it looks like when I run the script:
 Running the script generated by the Playwright codegen tool.
Running the script generated by the Playwright codegen tool.
Updating the script for my needs
The Playwright "codegen" generated script was a great starting point for web-scraping swing dancer data. However, it has two problems. First, the input is specific to my name. I want the script to accept any name (or dancer ID) as input. Second, the script doesn't retrieve the dancer's data from the page after performing the actions. It just exits immediately. Let's address these two problems one at a time.
Accepting dynamic user input
I want the script to accept a name or dancer ID as input, so I'll adjust the script like so:
from Playwright.sync_api import Playwright, Page, Browser, BrowserContext, sync_playwright
def check_points_inner(
page: Page, name_or_id: str
) -> None:
"""Check dancer points with the World Swing Dance Council site."""
i_frame = page.frame_locator('iframe[name="myiFrame"]')
search_bar = i_frame.get_by_placeholder("Search by Name or WSDC #")
search_bar.click()
search_bar.fill(name_or_id)
search_results = i_frame.locator(".tt-selectable")
try:
search_results.first.click(timeout=2000)
except TimeoutError:
return
def setup_playwright(playwright: Playwright) -> tuple[Browser, BrowserContext, Page]:
"""Set up playwright."""
browser = playwright.chromium.launch(headless=False, slow_mo=1000)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.worldsdc.com/registry-points/")
return browser, context, page
def teardown_playwright(browser: Browser, context: BrowserContext) -> None:
"""Tear down playwright."""
context.close()
browser.close()
def check_points(name_or_id: str) -> None:
"""Check dancer points with the World Swing Dance Council site."""
with sync_playwright() as playwright:
browser, context, page = setup_playwright(playwright)
try:
check_points_inner(page, name_or_id)
finally:
teardown_playwright(browser, context)
if __name__ == "__main__":
name_or_id = input("Name or ID: ")
check_points(name_or_id)
This script runs and works as intended. It performs identically to the auto-generated script when my name, "Theodore Williams", is used for the input. So what changes did I make? I'll explain the changes from the bottom to the top since the changes make more sense in this direction.
if __name__ == "__main__":
name_or_id = input("Name or ID: ")
check_points(name_or_id)
if __name__ == "__main__" is a typical if block for python scripts. It says, "Only run this bit of code if the python file is called as a script" (perhaps with python FILE_NAME on the command line). name_or_id = input("Name or ID: ") will prompt the user to input a "Name or ID". We set the value of that input to the variable name_or_id. Then we pass the name_or_id variable to a new function, check_points. Let's look at the function check_points.
def check_points(name_or_id: str) -> None:
"""Check dancer points with the World Swing Dance Council site."""
with sync_playwright() as playwright:
browser, context, page = setup_playwright(playwright)
try:
check_points_inner(page, name_or_id)
finally:
teardown_playwright(browser, context)
with sync_playwright() as playwright: starts a synchronous playwright context block, where we will perform all our playwright actions, just like in the auto-generated script. Inside the context block, we call three functions. setup_playwright, which establishes our playwright environment, check_points_inner, which performs the actions on the page; and teardown_playwright, which closes resources generated by setup_playwright. To ensure we always close resources, even if an error occurs, we call check_points_inner in a try block and teardown_playwright in a finally block. Therefore, no matter what happens in the try block, the finally block will be called. Let's look at each of those functions individually.
def setup_playwright(playwright: Playwright) -> tuple[Browser, BrowserContext, Page]:
"""Set up playwright."""
browser = playwright.chromium.launch(headless=False, slow_mo=1000)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.worldsdc.com/registry-points/")
return browser, context, page
The setup_playwright function copies the start of the run function we automatically generated earlier. First, it launches a new browser, browser_context, and page, and then it goes to the page we are interested in for web scraping. Finally, it returns all the resources we generated so we can use them in our other functions.
def teardown_playwright(browser: Browser, context: BrowserContext) -> None:
"""Tear down playwright."""
context.close()
browser.close()
The teardown_playwright function copies the end of the run function we automatically generated earlier, closing the browser and browser context we opened in setup_playwright.
def check_points_inner(
page: Page, name_or_id: str
) -> None:
"""Check dancer points with the World Swing Dance Council site."""
i_frame = page.frame_locator('iframe[name="myiFrame"]')
search_bar = i_frame.get_by_placeholder("Search by Name or WSDC #")
search_bar.click()
search_bar.fill(name_or_id)
search_results = i_frame.locator(".tt-selectable")
try:
search_results.first.click(timeout=2000)
except TimeoutError:
return
The check_points_inner function is the meat of our web-scraping work. All the work is performed on items located on the page object we generated in the setup_playwright function. This function is an update of our auto-generated run function from earlier that looked like this:
page.frame_locator("iframe[name=\"myiFrame\"]").get_by_placeholder("Search by Name or WSDC #").click()
page.frame_locator("iframe[name=\"myiFrame\"]").get_by_placeholder("Search by Name or WSDC #").fill("theodore williams")
page.frame_locator("iframe[name=\"myiFrame\"]").get_by_text("Theodore Williams (11612)").click()
First, I noticed that the code page.frame_locator("iframe[name=\"myiFrame\"]") is used three times in the original script. So I pulled it into its own variable for reusability and readability: i_frame = page.frame_locator('iframe[name="myiFrame"]'). Next, the code .get_by_placeholder("Search by Name or WSDC #") is reused twice, so I pulled this into its own variable as well: search_bar = i_frame.get_by_placeholder("Search by Name or WSDC #"). Next, we mouse-click the search bar from the previous line and fill in the search bar with the name_or_id we received as user input.
Filling in the search bar causes a dropdown menu to appear on the website. Previously, we clicked on the item from the dropdown with .get_by_text("Theodore Williams (11612)").click(). However, since the user input won't always be "Theodore Williams", this selector won't work. So how can we find that first search result without knowing its text contents? With CSS selectors.

If I go to the page I want to scrape in my browser, manually perform the search bar fill-in and hover the dropdown result; I can use the browser developer tools to find the CSS selector for the element I want. I do this in Chrome by right-mouse-clicking the dropdown result and clicking "inspect". Chrome pulls up its developer tools and highlights the inspected element in the page's HTML. The HTML element highlighted by the inspect tool looks like this:
<div class="tt-suggestion tt-selectable">Theodore Williams (11612)</div>
Therefore, to get the search result element with Playwright, we can chain a locator from the outer iframe using the CSS class tt-selectable. Remember, CSS selectors for element classes have a leading . so the result is search_results = i_frame.locator(".tt-selectable"). Finally, we click the search result with .click(). But what about the other changes?
try:
search_results.first.click(timeout=2000)
except TimeoutError:
return
The above code handles the problem we get if we don't find precisely one dancer. If the search finds more than one dancer, the locator i_frame.locator(".tt-selectable") would correspond to a list of search results. .first selects the first result in that list. But what if the search turns up zero dancers? In this case, the dropdown won't appear, meaning there will be zero elements with the tt-selectable class.
Playwright is clever and understands that JavaScript is not instant, so the element we want to click on might only be available after some time. In this case, Playwright will try clicking the element repeatedly until the click succeeds. If the click never succeeds, the click method will eventually throw a TimeOutError. By default, the click method will throw a TimeOutError after 30 seconds (or 30,000 milliseconds). However, since we are confident the dropdown menu will find a dancer in the first two seconds after typing a name (probably in less than one second), we can update this timeout to 2 seconds (or 2,000 milliseconds). Then, we can catch the error with a try/except block if a timeout occurs. For now, we'll return nothing, erroring silently. In the next step, we'll update the return value, so the error isn't silent.
Web-scraping dancer data
So far, we've had Playwright perform actions that bring a dancer's data into view. Next, we'll scrape that data from the page and return the data as JSON. Here's how I adjusted the script to scrape dancer data:
from typing import Union
import json
from Playwright.sync_api import Playwright, Page, Browser, BrowserContext, sync_playwright
def check_points_inner(
page: Page, name_or_id: str
) -> dict[str, Union[int, str, None]]:
"""Check dancer points with the World Swing Dance Council site."""
# Search for dancer
i_frame = page.frame_locator('iframe[name="myiFrame"]')
search_bar = i_frame.get_by_placeholder("Search by Name or WSDC #")
search_bar.click()
search_bar.fill(name_or_id)
search_results = i_frame.locator(".tt-selectable")
try:
search_results.first.click(timeout=2000)
except TimeoutError:
return {"error": "No results found."}
# Scrape results
results = i_frame.locator("#lookup_results")
name_and_id = results.locator("h1").inner_text()
name, dancer_id = name_and_id.split(" (")
dancer_id = dancer_id.strip(")")
lower_level = results.locator(".lead").first.locator(".label-success").inner_text()
upper_level_loc = results.locator(".lead").first.locator(".label-warning")
upper_level = upper_level_loc.inner_text() if upper_level_loc.is_visible() else None
div_and_points = results.locator("h3").first.inner_text()
highest_pointed_division, points_in_division, _ = div_and_points.split(" ")
return {
"name": name,
"id": int(dancer_id),
"lower_level": lower_level,
"upper_level": upper_level,
"highest_pointed_division": highest_pointed_division,
"points_in_division": int(points_in_division),
}
def setup_playwright(playwright: Playwright) -> tuple[Browser, BrowserContext, Page]:
"""Set up playwright."""
browser = playwright.chromium.launch(headless=False, slow_mo=1000)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.worldsdc.com/registry-points/")
return browser, context, page
def teardown_playwright(browser: Browser, context: BrowserContext) -> None:
"""Tear down playwright."""
context.close()
browser.close()
def check_points(name_or_id: str) -> dict[str, Union[int, str, None]]:
"""Check dancer points with the World Swing Dance Council site."""
with sync_playwright() as playwright:
browser, context, page = setup_playwright(playwright)
try:
return check_points_inner(page, name_or_id)
finally:
teardown_playwright(browser, context)
if __name__ == "__main__":
name_or_id = input("Name or ID: ")
results = check_points(name_or_id)
print(json.dumps(results, indent=4))
What changed? First, check_points now returns the result of check_points_inner, and check_points_inner returns a dictionary. We'll talk about the dictionary's contents momentarily. Then, in our if __name__ == "__main__": block for running the script, we put the dictionary results of check_points into a variable named results, and we print out that dictionary as a JSON string.
Now let's look at how we generate the dictionary in check_points_inner:
def check_points_inner(
page: Page, name_or_id: str
) -> dict[str, Union[int, str, None]]:
"""Check dancer points with the World Swing Dance Council site."""
# Search for dancer
i_frame = page.frame_locator('iframe[name="myiFrame"]')
search_bar = i_frame.get_by_placeholder("Search by Name or WSDC #")
search_bar.click()
search_bar.fill(name_or_id)
search_results = i_frame.locator(".tt-selectable")
try:
search_results.first.click(timeout=2000)
except TimeoutError:
return {"error": "No results found."}
# Scrape results
results = i_frame.locator("#lookup_results")
name_and_id = results.locator("h1").inner_text()
name, dancer_id = name_and_id.split(" (")
dancer_id = dancer_id.strip(")")
lower_level = results.locator(".lead").first.locator(".label-success").inner_text()
upper_level_loc = results.locator(".lead").first.locator(".label-warning")
upper_level = upper_level_loc.inner_text() if upper_level_loc.is_visible() else None
div_and_points = results.locator("h3").first.inner_text()
highest_pointed_division, points_in_division, _ = div_and_points.split(" ")
return {
"name": name,
"id": int(dancer_id),
"lower_level": lower_level,
"upper_level": upper_level,
"highest_pointed_division": highest_pointed_division,
"points_in_division": int(points_in_division),
}
This function is identical to the function from the last section until our except clause. Now, since we always want to return a dictionary, we return a dictionary explaining "No results found" if the dancer search returns no dancers to click before the two-second timeout.
Then, we scrape the results from the dancer search using chained Playwright locators to select the data and return those values in a dictionary. The locators find the data with CSS selectors that I looked up using the browser's "inspect" developer tool, just like before. Here's a GIF showing how I found the CSS selectors for the locators with Chrome's inspect tool.
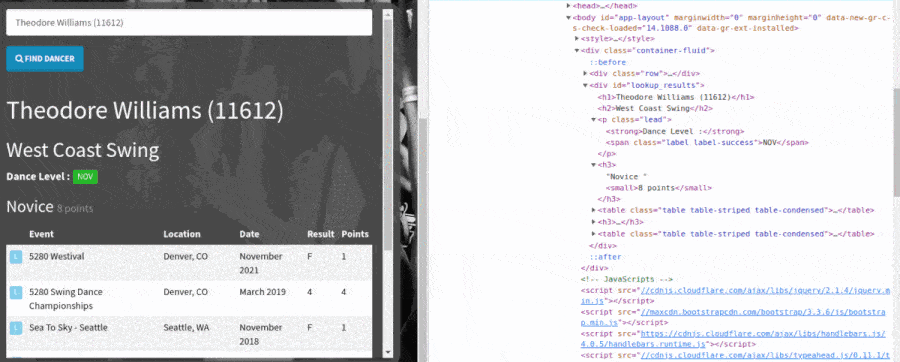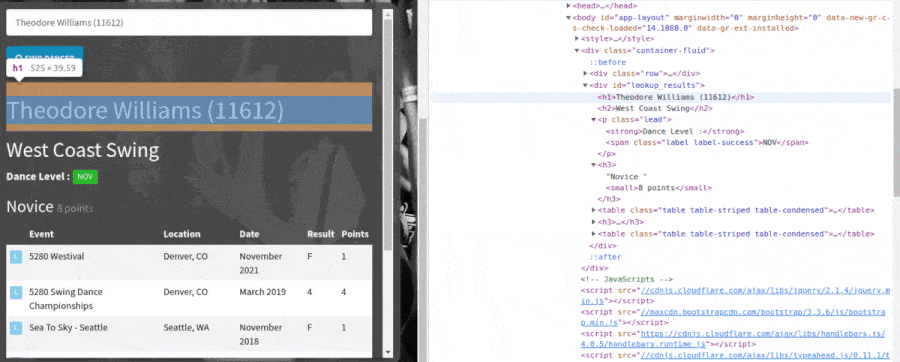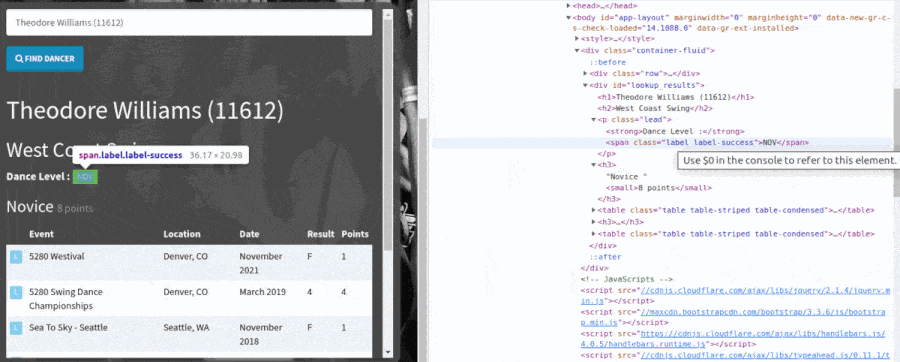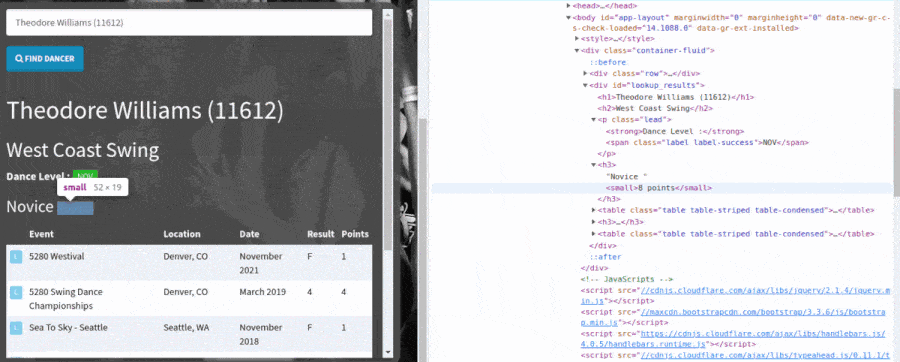 Scrape page data using Playwright locators and CSS selectors.
Scrape page data using Playwright locators and CSS selectors.
Side note: notice the "upper_level" and "lower_level" dictionary keys. Swing dancers from one division (for instance, Novice) gain points until they achieve a threshold that allows them to compete in a higher division (for example, Intermediate). However, until they earn points in the higher-level division, they can compete in both higher- and lower-level divisions. The website will list both divisions (or levels) when this happens. When the website lists both divisions, we scrape and return both values. We put the lower division in the "lower_level" field and the higher division in the "upper_level" field.

The final product
So far, I have introduced a script for scraping dancer data from the World Swing Dance Council website. Next, we will create a small Flask application with an endpoint that uses our web-scraping functions to return dancer data over the web. Here's the final code, including the Flask application endpoint.
"""check_dancer_points: Check dancer points with the World Swing Dance Council site."""
from typing import Union
from Playwright.sync_api import sync_playwright, TimeoutError, Page, Browser, BrowserContext, Playwright
import json
from flask import Flask, request
TIMEOUT = 2000
app = Flask(__name__)
@app.route("/")
def points_route() -> dict:
"""Return the points for a dancer as JSON (flask converts dictionary to JSON)."""
name_or_id = request.args.get("name_or_id")
return (
check_points(name_or_id) if name_or_id else {"error": "No name or ID provided."}
)
def check_points_inner(
page: Page, name_or_id: str
) -> dict[str, Union[int, str, None]]:
"""Check dancer points with the World Swing Dance Council site."""
# Search for dancer
i_frame = page.frame_locator('iframe[name="myiFrame"]')
search_bar = i_frame.get_by_placeholder("Search by Name or WSDC #")
search_bar.click()
search_bar.fill(name_or_id)
search_results = i_frame.locator(".tt-selectable")
try:
search_results.first.click(timeout=TIMEOUT)
except TimeoutError:
return {"error": "No results found."}
# Scrape results
results = i_frame.locator("#lookup_results")
name_and_id = results.locator("h1").inner_text()
name, dancer_id = name_and_id.split(" (")
dancer_id = dancer_id.strip(")")
lower_level = results.locator(".lead").first.locator(".label-success").inner_text()
upper_level_loc = results.locator(".lead").first.locator(".label-warning")
upper_level = upper_level_loc.inner_text() if upper_level_loc.is_visible() else None
div_and_points = results.locator("h3").first.inner_text()
highest_pointed_division, points_in_division, _ = div_and_points.split(" ")
return {
"name": name,
"id": int(dancer_id),
"lower_level": lower_level,
"upper_level": upper_level,
"highest_pointed_division": highest_pointed_division,
"points_in_division": int(points_in_division),
}
def setup_playwright(playwright: Playwright) -> tuple[Browser, BrowserContext, Page]:
"""Set up playwright."""
browser = playwright.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.worldsdc.com/registry-points/")
return browser, context, page
def teardown_playwright(browser: Browser, context: BrowserContext) -> None:
"""Tear down playwright."""
context.close()
browser.close()
def check_points(name_or_id: str) -> dict[str, Union[int, str, None]]:
"""Check dancer points with the World Swing Dance Council site."""
with sync_playwright() as playwright:
browser, context, page = setup_playwright(playwright)
try:
return check_points_inner(page, name_or_id)
finally:
teardown_playwright(browser, context)
if __name__ == "__main__": # pragma: no cover
name_or_id = input("Name or ID: ")
results = check_points(name_or_id)
print(json.dumps(results, indent=4))
What changed? Here's the most noticeable change.
app = Flask(__name__)
@app.route("/")
def points_route() -> dict:
"""Return the points for a dancer as JSON (flask converts dictionary to JSON)."""
name_or_id = request.args.get("name_or_id")
return (
check_points(name_or_id) if name_or_id else {"error": "No name or ID provided."}
)
This code snippet creates a simple Flask application and a single endpoint at /. The endpoint expects a query string with the parameter "name_or_id". The function passes the provided "name_or_id" query string parameter value into our check_points function. That function returns a dictionary with the dancer's data, returning an error instead if no "name_or_id" query string parameter is provided. Finally, flask converts the dictionary to JSON and returns that JSON in the response body.
The other most notable change is that we replaced the setup_playwright function line browser = playwright.chromium.launch(headless=False, slow_mo=1000) with browser = playwright.chromium.launch(headless=True). We launch the browser in headless mode without "slow_mo" because we don't need to see a chrome window open and perform the web scraping. This change makes the scraping perform much faster.
To launch the Flask application, run the following:
flask --app check_dancer_points run --reload
Then open a web browser to http://localhost:5000. When we open a browser to http://localhost:5000, we'll see the error {"error": "No name or ID provided."}. We must provide the required "name_or_id" query string parameter. Let's try opening the page with this query string: http://localhost:5000/?name_or_id=theodore%20williams (note: "%20" is the URL encoding for a space " "). With the query string provided, the resulting output body looks like this (after indenting):
{
"highest_pointed_division": "Novice",
"id": 11612,
"lower_level": "NOV",
"name": "Theodore Williams",
"points_in_division": 8,
"upper_level": null
}
Success! We have a working Flask application capable of scraping dancer data from the World Swing Dance Council website using Playwright.
Testing the application
No code is complete without automated tests to ensure everything is working as expected. Here's a test file to test our Flask endpoint under a few conditions.
"""Tests for check_dancer_points.py."""
import pytest
from pytest import MonkeyPatch
from flask.testing import FlaskClient
from check_dancer_points import app
import check_dancer_points
@pytest.fixture()
def client() -> FlaskClient:
"""Create a fresh flask client for a function."""
return app.test_client()
def test_no_name_or_id(client: FlaskClient) -> None:
"""Test that no name or ID provided returns an error."""
response = client.get("/")
assert response.json == {"error": "No name or ID provided."}
def test_no_results(client: FlaskClient, monkeypatch: MonkeyPatch) -> None:
"""Test that no results found returns an error."""
monkeypatch.setattr(check_dancer_points, "TIMEOUT", 1)
response = client.get("/?name_or_id=not%20a%20dancer")
assert response.json == {"error": "No results found."}
def test_name_and_id(client: FlaskClient) -> None:
"""Test that name and ID are returned."""
response = client.get("/?name_or_id=Theodore%20Williams") # That's me!
assert response.json and "error" not in response.json
assert response.json["name"] == "Theodore Williams"
assert response.json["id"] == 11612
If you're not familiar with testing python code with pytest, check out my blog post "9 pytest tips and tricks to take your tests to the next level". The above tests make use of a single fixture called client. The fixture uses an import of our Flask app to create and return a Flask test client. The three test functions use the Flask test client by providing client as a parameter to the test.
All three tests call the / endpoint. The first test calls the endpoint without the required query string and asserts that the appropriate error is returned. The second test provides a query string for a non-existent dancer and asserts the relevant error is returned. It also monkey patches the TIMEOUT from 2000 milliseconds down to 1 millisecond to speed up the test. You can read about monkey patching global variables in my pytest blog post. The final test checks the endpoint with a working dancer name (my name) and asserts that the returned name and dancer ID are as expected.
Conclusions
In this blog post, we learned how to scrape a website's data with Playwright and how to test a Flask application that makes use of Playwright web scraping. Playwright is a valuable tool for scraping websites that rely on javascript, requiring human-like page interactions to expose the desired data. I hope you found this tutorial useful! 😃
About the author

Hi, my name is Teddy Williams. I'm a software developer with a special love for python programming. 🐍👨💻 I have a wide range of programming interests including web development, hobby video game development, IoT, data science and just writing scripts to automate everyday boring tasks. I'd love it if you check out some of my other posts or take a look at my portfolio! :)
Thanks for reading this post! 💚 If you like the post, let me know by hitting the icon below, and if you have any questions or comments I'd love to hear them in the comments section. Thanks, and happy coding! 🎉